TSL语言基础 > SQL基础到TS-SQL > TS-SQL入门 > select查询语句
where进行条件查询
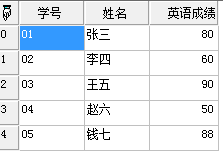
- 假如我们有一个二维数组EnglishScore,结构如下:
学号姓名英语成绩
01 张三 80
02 李四 60
03 王五 90
04 赵六 50
05 钱七 88
我们现在有一个需求,我们需要查找出成绩大于85分的人的情况,并存贮在数组B中。通过我们已经掌握的知识,我们知道,通过一个循环语句可以解决这个问题。
假定EnglishScore是一个二维数组并已经存贮了英语成绩表。
B:=array();
Index:=0;
For i:=0 to length(EnglishScore)-1 do
Begin
If EnglishScore [i]["英语成绩"]>85 then
Begin
B[Index]:= EnglishScore [i]; //将A的i行的内容赋给B的Index行
Index++;
End;
End;
这样我们得到了一个B,存贮的是英语成绩大于85的英语成绩信息。
我们来看另外一种写法:
B:=Select * from EnglishScore where ["英语成绩"]>85 end;
这样看起来是不是很简洁呢?我们是否发现这种写法更容易理解呢?事实上,SQL语法比较接近自然语言,我们可以把以上语法理解为:查询所有的从 EnglishScore 中的英语成绩> 85的记录。
Select from结果集之后,允许跟 where以及一个查询条件,这个约定俗成称之为Where子句。
注:TS-SQL访问数据项是用[数组下标]的模式,而在真实的SQL中,假如有【英语成绩】这个字段,是不需要在【英语成绩】前后加引号的。例如在SQL中abcd或者[abcd]表示字段abcd,而不需要用["abcd"],但是在TSL中却例外,因为在TSL语言中,abcd表示变量,你可以采用给abcd赋值为"英语成绩",使用["abcd"]来表示["英语成绩"]。此外,SQL语法的SELECT是不需要END为结束符的,SQL语法的结束符和TSL类似,大多为分号“;”但如果遵循该规则,B:=Select * from EnglishScore where ["英语成绩"]>85 end;写成B:=Select * from EnglishScore where ["英语成绩"]>85;;就很难看了,第一个;表示select的结束,第二个;表示:=语句的结束。