TSL语言基础 > SQL基础到TS-SQL > TS-SQL入门 > select查询语句 > SELECT统计与分组、聚集函数
Group by 进行分组与Having进行分组后的结果筛选
- 如果我们现在的需求进行了一个变化,我们需要得到的是不及格的人数和平均分,中等60-70分的人数和平均分,良好70-85的人数和平均分,85以上优秀的平均分。
这样的需要我们可以采用多条SELECT语句来分别实现各个成绩段的统计。但是SQL同样提供了直接的方法。我们看以下的写法:
Return SELECT AvgOf(["英语成绩"]),CountOf( * ),groupfunc(["英语成绩"]) from EnglishScore group by groupfunc(["英语成绩"]) end;
Function groupfunc(score);
Begin
If score<60 then return "不及格"
Else
If Score <70 then return "中等"
Else
If Score < 85 then return "良好"
Else
Return "优秀";
End;
上述代码我们可以如此理解:groupfunc只是一个自己定义的函数,用途仅仅只是为了上面的分组需要,因为英语成绩表中并没有什么是优秀什么是及格的标准。
GroupFunc把成绩分成了四档,而group by则把这四档进行分组,Avgof和countof对分组的内容进行聚集计算。如何理解呢?Avgof在没有group by的时候是对整个结果集进行处理,而有group by的时候是对分组后的每个子结果集进行运算处理。
上述代码的返回结果为:
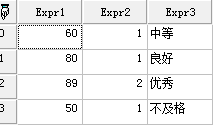
如果我们需要的内容是返回个数>1的。那么我们的语句为:
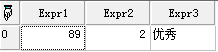
Return SELECT AvgOf(["英语成绩"]),CountOf( * ),groupfunc(["英语成绩"]) from EnglishScore group by groupfunc(["英语成绩"]) Having CountOf( * ) >1 end;
运行结果如下:
Having和Where是不是很类似呢?许多初学SQL的人会很容易混淆两者的差异,事实上Having可以用聚集函数作为条件,而Where是不行的,Having是先group分组再计算having条件,而where则是最先开始进行条件筛选。在group by之前是允许有where条件的。