FAQ > 金融建模 > 效率优化 > 数据处理效率优化
Q:如何快速在大数据集中筛选多列同时满足条件的子数据集?
- A:在一个数据集中筛选同时满足多列按不同条件汇总的子数据集时,可构建一个由需条件判断的列组成的和原数据集相同长度的零数组,
处理该子数组把满足条件单元格值设为真,获取所有列为真的行,最后在原数组中取满足条件的行的子数据即可。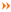 实现示例
实现示例
在一个数据集中筛选同时满足:1.净利润前80%;2.市值前50%;3.市盈率后80%;4.涨幅前80%;5.换手率后80% 的子数组
范例代码:endt:=20240920t;
setsysparam(pn_date(),endt);
//初始化原数组
data:=Query('A股','',true,'',
'代码',DefaultStockID(),
'名称',CurrentStockName(),
'季度净利润',LastQuarterData(NewReportDateOfEndT2(endt),46033),
'市值',StockTotalValue3(),
"市盈率",StockPE(EndT),
"涨幅",stockzf3(),
"换手率",stockhsl3());
//需要条件判段的列
cols:=mcols(data,1)[2:6];
//初始化和原数组相同长度的零数组
arr:=Zeros(mrows(data),cols);
//1.净利润前80%
arr[:,cols[0]]:=data[:,cols[0]].>=PercentValueByField(data,cols[0],0.2);
//2.市值前50%
arr[:,cols[1]]:=data[:,cols[1]].>=PercentValueByField(data,cols[1],0.5);
//3.市盈率后80%
arr[:,cols[2]]:=data[:,cols[2]].>=PercentValueByField(data,cols[2],0.8);
//4.涨幅前80%
arr[:,cols[3]]:=data[:,cols[3]].>=PercentValueByField(data,cols[3],0.2);
//5.换手率后80%
arr[:,cols[4]]:=data[:,cols[4]].<=PercentValueByField(data,cols[4],0.8);
//满足所有条件的行
rows:=sselect thisrowindex from arr where sum(thisrow)=length(cols) end;
//在原数组中取子数组
return data[rows];相关说明
FAQ:PercentValueByField
FAQ:基础算符对矩阵计算的支持